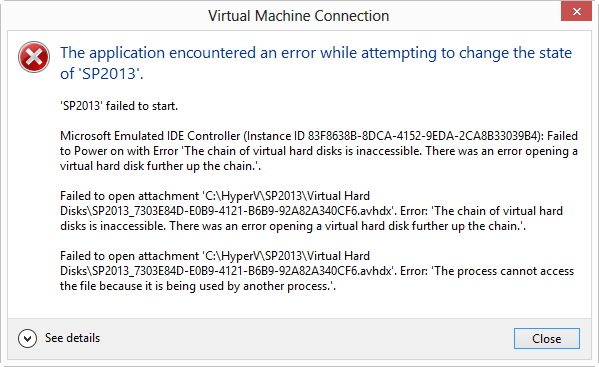
Hello,
We have experienced a multiple VM failures and 2 cluster node reboots in a seven node Windows Server 2012 cluster.
Multiple virtual machines crashed as a result of „STATUS_CONNECTION_DISCONNECTED(c000020c)“ error reported for multiple CSV LUNs on multiple Hyper-V nodes. This is one example of these errors:
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 26.2.2014. 22:12:03
Event ID: 5120
Task Category: Cluster Shared Volume
Level: Error
Keywords:
User: SYSTEM
Computer: CL01N04.domain.local
Description:
Cluster Shared Volume 'HYPERV_LUN_9 (SAS)' ('HYPERV_LUN_9 (SAS)') is no longer available on this node because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Two Hyper-V nodes crashed, node 5 and node 7. This was reported in the error log for one of the nodes:
Log Name: System
Source: EventLog
Date: 26.2.2014. 22:16:54
Event ID: 6008
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: CL01N05.domain.local
Description:
The previous system shutdown at 22:11:37 on 26.2.2014. was unexpected.
Log Name: System
Source: Microsoft-Windows-WER-SystemErrorReporting
Date: 26.2.2014. 22:16:57
Event ID: 1001
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: CL01N05
Description:
The computer has rebooted from a bugcheck. The bugcheck was: 0x0000009e (0xfffffa81b5557080, 0x00000000000004b0, 0x0000000000000000, 0x0000000000000000). A dump was saved in: C:\Windows\MEMORY.DMP. Report Id: 022614-43914-01.
Four CSV LUNs were emptied from VHDX disks because of virtual machine decommissioning. These four empty CSV LUNs were removed from cluster shared volumes using „Failover Cluster Manager“ console from node 1 using right-click „Remove from Cluster Shared Volumes“. During this operation the „Failover Cluster Manager“ console hanged during removal of each disk for about 10 minutes. The disks appeared as failed after the console refreshed itself and then they could be successfully removed from the console. It took another 20 minutes for the remaining CSV disks and virtual machines to start crashing. In the attachment are excerpts from the Cluster.txt log file with some important event logged just before crashed occurred. Most notable are the following:
00000a54.00001b0c::2014/02/26-20:51:23.285 ERR [GUM] Node 2: Local Execution of a gum request /rcm/gum/MarkGroupBusy resulted in exception ERROR_CLUSTER_GROUP_BUSY(5944)' because of 'Group is in the middle of some other operation'
00000a54.00001b0c::2014/02/26-20:51:23.285 ERR [RCM] rcm::RcmApi::ChangeResourceGroup: ERROR_CLUSTER_GROUP_BUSY(5944)' because of 'Group is in the middle of some other operation'
00000a54.0000221c::2014/02/26-20:51:58.869 ERR [RCM] rcm::RcmResControl::DoResourceControl: ERROR_RESOURCE_CALL_TIMED_OUT(5910)' because of 'Control(STORAGE_GET_DISK_INFO_EX) to resource 'Exchange2010' timed out.'
00000a54.0000221c::2014/02/26-20:51:58.869 WARN [RCM] ResourceControl(STORAGE_GET_DISK_INFO_EX) to Exchange2010 returned 5910.
(Note: Exchange2010 is the CSV disk being decommissioned)
00000a54.00002a18::2014/02/26-20:54:09.516 ERR [RCM] rcm::RcmResControl::DoResourceControl: ERROR_RESOURCE_CALL_TIMED_OUT(5910)' because of 'Control(STORAGE_GET_DISK_INFO_EX) to resource 'HYPERV_LUN_9 (SAS)' timed out.'
00000a54.00002c8c::2014/02/26-20:54:09.516 ERR [RCM] rcm::RcmResControl::DoResourceControl: ERROR_RESOURCE_CALL_TIMED_OUT(5910)' because of 'Control(STORAGE_GET_DISK_INFO_EX) to resource 'HYPERV_SQL_LUN_2 (SAS)' timed out.'
00000a54.00002a18::2014/02/26-20:54:09.516 WARN [RCM] ResourceControl(STORAGE_GET_DISK_INFO_EX) to HYPERV_LUN_9 (SAS) returned 5910.
00000a54.00002c8c::2014/02/26-20:54:09.516 WARN [RCM] ResourceControl(STORAGE_GET_DISK_INFO_EX) to HYPERV_SQL_LUN_2 (SAS) returned 5910.
(Note: CSV LUNs above are production LUNs with live virtual machines. After these events the virtual machines are starting to fail.)
DPM backup was running at the time of failure. We have experienced at least 4 previous crashes because of CSV disks being unavailable during DPM backup and as a result we have configuredCSV serialization.
We have the following cluster resiliency hotfixes installed:
- http://support.microsoft.com/kb/2878635
- http://support.microsoft.com/kb/2796995
- http://support.microsoft.com/kb/2813630
- http://support.microsoft.com/kb/2870270
- http://support.microsoft.com/kb/2838043
- http://support.microsoft.com/kb/2869923
This is analysis from a memory dump:
MODULE_NAME: netft
FAULTING_MODULE: fffff80010a15000 nt
DEBUG_FLR_IMAGE_TIMESTAMP: 5010aa07
PROCESS_OBJECT: fffffa81b5557080
DEFAULT_BUCKET_ID: WIN8_DRIVER_FAULT
BUGCHECK_STR: 0x9E
CURRENT_IRQL: 0
ANALYSIS_VERSION: 6.3.9600.16384 (debuggers(dbg).130821-1623) amd64fre
LAST_CONTROL_TRANSFER: from fffff8800591c845 to fffff80010a6f440
STACK_TEXT:
fffff880`009a37f8 fffff880`0591c845 : 00000000`0000009e fffffa81`b5557080 00000000`000004b0 00000000`00000000 : nt!KeBugCheckEx
fffff880`009a3800 fffff880`0591c516 : 00000000`00000002 fffff880`009a3b10 fffff880`009a3939 00000000`00000000 : netft+0x2845
fffff880`009a3840 fffff800`10a981ea : 00000000`00000002 00000000`00000000 fffff880`009a3b18 fffff800`1117de3b : netft+0x2516
fffff880`009a3870 fffff800`10a96655 : fffff880`009a3ab0 fffff800`10a97cff fffff880`00991f00 fffff880`009934e0 : nt!KeDelayExecutionThread+0x1a0a
fffff880`009a39a0 fffff800`10a98668 : fffff880`0098f180 fffff880`00991f80 00000000`00000001 00000000`06591183 : nt!memset+0x1be5
fffff880`009a3a40 fffff800`10a97a06 : 000006b1`f05f995d fffffa80`c25da010 000006b1`f05f995d fffff880`009a3b4c : nt!KeQueryInterruptTimePrecise+0x188
fffff880`009a3af0 fffff800`10a989ba : fffff880`0098f180 fffff880`0098f180 00000000`00000000 fffff880`0099b140 : nt!KeDelayExecutionThread+0x1226
fffff880`009a3c60 00000000`00000000 : fffff880`009a4000 fffff880`0099e000 00000000`00000000 00000000`00000000 : nt!KeQueryInterruptTimePrecise+0x4da
STACK_COMMAND: kb
FOLLOWUP_IP:
netft+2845
fffff880`0591c845 cc int 3
SYMBOL_STACK_INDEX: 1
SYMBOL_NAME: netft+2845
FOLLOWUP_NAME: MachineOwner
IMAGE_NAME: netft.sys
BUCKET_ID: WRONG_SYMBOLS
FAILURE_BUCKET_ID: WRONG_SYMBOLS
ANALYSIS_SOURCE: KM
FAILURE_ID_HASH_STRING: km:wrong_symbols
FAILURE_ID_HASH: {70b057e8-2462-896f-28e7-ac72d4d365f8}
Followup: MachineOwner
---------
Has anyone exprienced an issue like this?
Regards,
Dinko